| |
Allà pel període
pleistocè, quan hom aconseguia per primera vegada introduir informació
a un ordinador mitjançant un teclat de màquina d'escriure
(què, què és això? busca-ho en una enciclopèdia,
si et plau!, o bé demana-li a Google
informació quant a "Remington", "Underwood"
o "Olivetti") , és perquè hom havia codificat
els caràcters d'aquest teclat, és a dir, perquè havia
atribuït a cadascun dels caràcters un codi, això
és, un nombre enter, que l'ordinador podia desar i manipular amb
facilitat. |
|
| |
|
|
| |
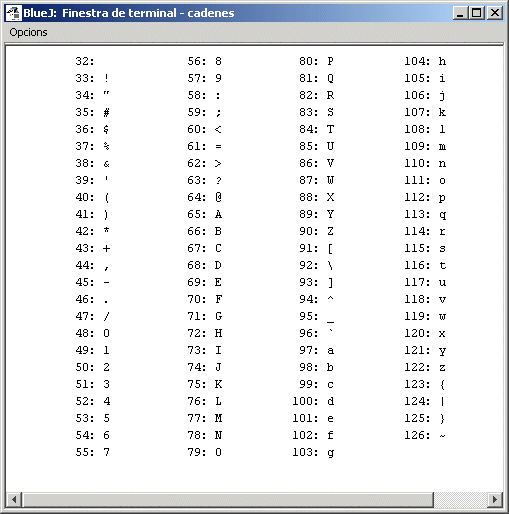
Ben aviat, amb el propòsit que la informació fós
intercanviable entre sistemes informàtics diversos, s'arribà
a un estàndar per a codificacions, mitjançant l'establiment
del codi ASCII
("American Standard Code for Information Interchange").
És aquest:
|
|
| |
|
|
| |
|
|
| |
|
|
| |
En realitat, el codi
ASCII comença a 0 i acaba a
127. Els caràcters de la taula anterior,
del 32 (espai) al 126
són els caràcters imprimibles, mentre els que van del
0 al 31 i el 127
són caràcters no imprimibles i descriuen certes accions
o ordres per a dispositius d'impressió: pots imaginar-los com codificacions
de les tecles que, directament, no imprimeixen res. Així, per exemple, |
|
| |
|
|
| |
| El codi |
9 |
correspon al caràcter d'escapament |
\t |
(tabulador) |
| El codi |
10 |
correspon al caràcter d'escapament |
\n |
(canvi de línia) |
|
|
| |
|
|
| |
Així, doncs, la paraula
"Dilluns", un cop codificada, es converteix en la llista
de nombres 68,105,108,108,117,110,115.
|
|
| |
|
|
| |
No tots eren americans, però... |
|
| |
|
|
| |
Pero, però...
no hi ha accents! ni tampoc hi és la "ç"!
I si volem que les màquines ens entenguin i ens escriguin en grec,
o rus, o japonès? Ja es veu que els creadors de la codificació
ASCII es basaren en el teclat d'una màquina d'escriure en anglès,
i només en aquest... |
|
| |
|
|
| |
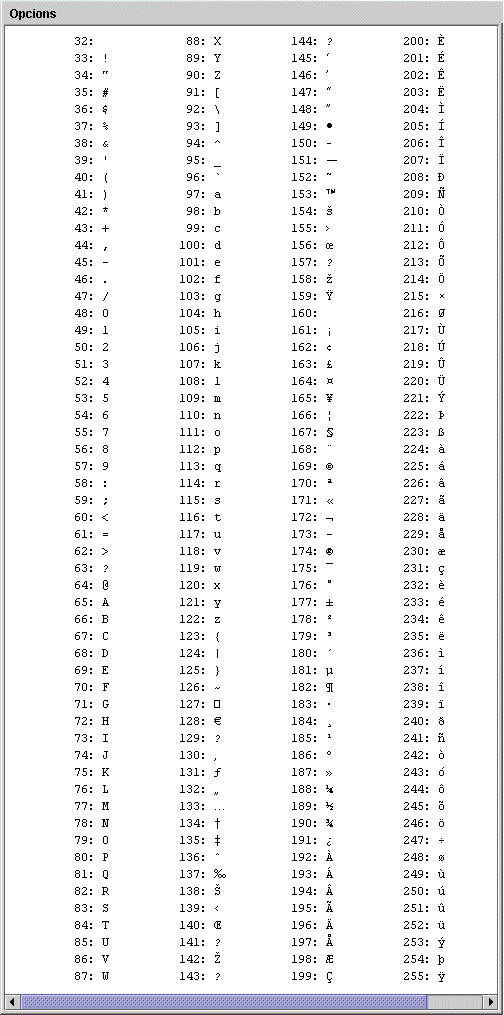
Encara hi havia,
però, cert marge: l'espai de memòria recessari per enmagatzemar
un caràcter és d'un byte, o sigui, vuit bits.
Això dóna 28
= 256 possibilitats, de les quals només se n'havien
gastat 128, del 0
al 127. Aparegueren llavors les taules ASCII
exteses, en les quals, l'atribució de caràcters
(caràcters especials, en deien) des del 128
al 175 era variable, en funció de les necessitats
(à, ü,
ç, ñ,
etc.) i la resta, fins el 255, consistia en símbols
diversos i trossos de línies i cantonades per enmarcar taules. |
|
| |
|
|
| |
La situació actual: la
codificació Unicode |
|
| |
|
|
| |
Ja es veu que les taules
ASCII exteses no poden ser capaces de respondre al munt enorme
d'alfabets i sistemes d'escriptura que els humans solem fer servir. Avui
s'ha imposat l'estàndar Unicode,
que "proporciona un nombre únic per a cada caràcter,
sense que importi la plataforma, sense que importi el programa, sense que
importi el idioma." segons s'estableix a
|
|
| |
|
|
| |
|
|
| |
|
|
| |
El mètode és simple:
tantes taules de codificació com alfabets hi hagi, tot mantenint
la codificació per a caràcters compartits per diverses taules.
Pots veure aquestes taules a |
|
| |
|
|
| |
|
|
| |
|
|
| |
Quina taula s'ha de fer servir
a cada cas és una informació que resideix a la màquina
de l'usuari, i tot el programari que hi hagi (i, per tant, Java)
escull automàticament la codificació adequada a partir d'aquesta
informació. |
|
| |
|
|
| |
En el nostre cas, de llengües
que usen l'alfabet llatí, la codificació Unicode
dels caràcters sense accentuar i d'alguns símbols usuals és
la mateixa que al codi
ASCII entre el 32 i el 126.
Aquesta n'és la taula |
|
| |
|
|
| |
|
|
| |
|
|
| |
Java i Unicode: bytes i chars,
codis, caràcters i cadenes |
|
| |
|
|
| |
Mentre el codi ASCII
era plenament vigent, les coses eren senzilles: una cadena (string)
no era més que una matriu amb els codis dels caràcters de
la cadena: |
|
| |
|
|
| |
| "Dilluns"={68,105,108,108,117,110,115};
// No vàlid a Java! |
|
|
| |
|
|
| |
Alguns llenguatges, C
per exemple, afegeixen un 0 al final com a marcador
de final de cadena: |
|
| |
|
|
| |
| "Dilluns"={68,105,108,108,117,110,115,0};
// No vàlid a Java! |
|
|
| |
|
|
| |
Però ara, amb Unicode,
quan 68 no és sempre una 'D',
Java no
en pot fer un tractament tan simple. |
|
| |
- D'una banda hi ha els codis, és a dir, els nombres.
Corresponen al tipus primitiu byte.
Un valor de tipus byte ocupa això,
un byte, és a dir, vuit bits. Per tant, hi ha 256
valors possibles (mira més
amunt). Java els disposa des del -128
al 127.
|
|
| |
| byte unByte=12;
// Atenció! entre -128 i 127 |
|
|
| |
- Després hi ha els caràcters, és a dir,
les lletres i símbols. Corresponen al tipus primitiu char
i un valor de tipus char és ja una
lletra, que correspon a un valor del tipus byte
segons la codificació activa:
|
|
| |
char unChar='C';
// Atenció! són apòstrofs (')
//no cometes (")
char unAltreChar=67 // El valor
és el caràcter 'C'
//
Atenció! entre -128 i 127
byte unByte='C'; //
El valor és 67 |
|
|
| |
- Finalment, una cadena (string) és un objecte de la classe
java.lang.String que es construeix a partir
d'una matriu de chars o de bytes:
|
|
| |
char[] matDeChars={'D','i','l','l','u','n','s'};
char[] matDeBytes={68,105,108,108,117,110,115};
String cadena_1=new String(matDeChars);
//El valor és "Dilluns"
String cadena_2=new String(matDeBytes);
// El valor és "Dilluns"
|
|
|
| |
a part d'allò que ja saps:
|
|
| |
|
String cadena_3="Dilluns";
|
|
|
| |
|
|
| |
Tampoc és tan complicat,
però, eh? bytes i chars
són perfectament intercanviables: els bytes
són nombres i els chars són el mateix,
però tenint en compte la codificació disponible. |
|
| |
|
|
| |
La classe
java.lang.String conté un munt de mètodes
per manipular els chars i bytes
d'una cadena: |
|
| |
|
|
| |
- public String (byte[]
bytes). Mètode constructor per a objectes de la classe
java.lang.String. Construeix la cadena a partir
de la descodificació dels bytes de
la matriu bytes.
- public String (char[]
chars). Mètode constructor per a objectes de la classe
java.lang.String. Construeix la cadena a partir
dels chars de la matriu chars.
- public char charAt(int
index). Retorna el char que és
a la posició índex (el primer
caràcter té index 0).
- public byte[] getBytes().
Retorna la matriu de bytes corresponents als
caràcters que formen la cadena, descodificats.
- public int indexOf(int
ch). Retorna la posició de la primera vegada que apareix
el caràcter de descodificació el nombre ch.
- public int indexOf(int
ch,int index). El mateix que l'anterior, però la cerca
no comença al principi de la cadena sinó a partir de la
posició index.
- public int lastIndexOf(int
ch). Retorna la posició de l'última vegada que
apareix el caràcter de descodificació el nombre ch.
- public int lastIndexOf(int
ch,int index). El mateix que l'anterior, però la cerca
no comença al final de la cadena sinó a partir de la posició
index.
- public String replace(char
vellChar,char nouChar). Canvia tots els caràcters vellChar
que contingui la cadena pel caràcter nouChar.
- public char[] toCharArray().
Retorna la matriu de chars que formen la cadena.
|
|
| |
|
|
| |
Un programa d'encriptació: |
|
| |
|
|
 |
Ara podem posar en funcionament
tot això i, de passada, respondre a la pregunta que, segur,
t'estàs fent: de què serveix tota aquesta complicació?
quina gràcia té que els caràcters, les lletres, siguin,
en realitat, nombres? |
|
| |
|
|
| |
L'art de transmetre missatges que
siguin completament inintel·ligibles per a altres persones que no
siguin l'emissor i el receptor és molt antic i de gran utilitat,
per exemple, en la guerra. Juli
Cèsar feia servir aquest mètode: després
d'escriure el missatge: |
|
| |
|
|
| |
GALLI
IRRVMATORES SVNT
|
|
| |
|
|
| |
(que no hauria agradat gens a Astèrix)
substituia cadascuna de les lletres per la que estava dos llocs més
endavant a l'alfabet. El resultat és: |
|
| |
|
|
| |
ICNNL
LTTYOCXQTGV VYPX
|
|
| |
|
|
| |
(A l'alfabet llatí clàssic
no hi ha ni "J" ni "U"). |
|
| |
|
|
| |
Podem fer una classe que faci precisament
aixó. Obre un nou projecte que es digui Encriptacio
i afegeix-li aquesta classe: |
|
| |
|
|
 |
|
/**
* Encriptació i desencriptació pel mètode
del Cèsar restringit
* als caràcters ASCII imprimibles (32 a 126).
*
* @author Carles Romero
* @version 2004/01/10
*/
public class CesarASCII {
/**
* La translació que sofriran
els caràcters en encriptar (+)
* i/o desencriptar (-).
*/
int translacio=0;
/**
* Mètode constructor per a
aquesta encriptació del Cèsar.
* @param laTranslacio la translació
que sofriran els
* caràcters en encriptar (+)
i/o desencriptar (-)
*/
public
CesarASCII (int laTranslacio) { // constructor
translacio=laTranslacio;
}
|
|
|
| |
|
|
| |
De moment, només hi ha la
variable d'instància translacio (inicialitzada
a 0) i un mètode constructor en el qual
es demana, com a paràmetre, el valor d'aquesta variable. Ja pots
compilar-la, construir-ne un objecte i inspeccionar-la... |
|
| |
|
|
| |
Ara hi posaràs el mètode
que fa la feina: com que l'encriptació consisteix en sumar al byte
que codifica una certa lletra el valor de translació
i desencriptar consisteix en restar-li-lo, podem fer que int
+1 sigui l'indicador d'encriptació i int
-1 el de desencriptació. El mètode es pot dir: |
|
| |
|
|
| |
| private
byte trasllada (byte bIn,int mesOmenys) { |
|
|
| |
|
|
| |
byte bIn
és el byte a traslladar i int mesOmenys
és +1 o -1 segons
convingui. |
|
| |
|
|
| |
El primer pas és traslladar
l'origen de bytes a 0 (ara és a 32).
És fàcil: |
|
| |
|
|
| |
| int
iBIn=(int)bIn-32; // Fer començar
la codificació a 0 |
|
|
| |
|
|
| |
(Observa que, per tal que les coses
funcionin, cal fer càsting del tipus byte
al tipus int) |
|
| |
|
|
| |
Després, com que del caràcter
32 al caràcter 126
(que són els caràcters imprimibles ASCII) n'hi ha 95,
ens hem d'assegurar que la variable int mou, que
és la que se sumarà al byte, |
|
| |
|
|
| |
| int
mou=(mesOmenys*translacio)%95; |
|
|
| |
|
|
| |
if
(mou<0) { // Assegurar que mou >=
0
mou=mou+95;
} |
|
|
| |
Ara ja pots fer la translació,
tot vigilant que el resultat no passi de 95: |
|
| |
|
|
| |
|
|
| |
|
|
| |
Finalment, ja pots retornar el
valor, després de tornar a posar l'origen a 32
i fer el corresponent càsting: |
|
| |
|
|
| |
|
|
| |
|
|
| |
La classe quedarà ara així: |
|
| |
|
|
|
|
/**
* Encriptació i desencriptació pel mètode
del Cèsar restringit
* als caràcters ASCII imprimibles (32 a 126).
*
* @author Carles Romero
* @version 2004/01/10
*/
public class CesarASCII {
/**
* La translació que sofriran
els caràcters en encriptar (+)
* i/o desencriptar (-).
*/
int translacio=0;
/**
* Mètode constructor per a
aquesta encriptació del Cèsar.
* @param laTranslacio la translació
que sofriran els
* caràcters en encriptar (+)
i/o desencriptar (-)
*/
public CesarASCII (int laTranslacio) { //
constructor
translacio=laTranslacio;
}
|
|
private
byte trasllada (byte bIn,int mesOmenys) {
int
iBIn=(int)bIn-32; // Fer començar
la codificació a 0
int
mou=(mesOmenys*translacio)%95; // del
32 al 126 hi
//
ha 95 caràcters
if
(mou<0) { // Assegurar que mou >=
0
mou=mou+95;
}
iBIn=(iBIn+mou)%95;
iBIn=iBIn+32;
// Tornar a la codificació ASCII
standard
return
(byte)iBIn;
}
|
} |
|
|
| |
|
|
| |
El pas següent és fer
aquesta feina sobre tots els caràcters d'una cadena. Necessites un
altre mètode que ho faci: |
|
| |
|
|
| |
private
String encriptaOdesencripta
(String stringEntrada, int encriptar) { |
|
|
| |
|
|
| |
El paràmetre encriptar serà,
com abans, +1 o -1 segons
calgui encriptar o desencriptar. Caldrà obtenir la matriu de bytes
que codifiquen la cadena d'entrada stringEntrada, |
|
| |
|
|
| |
| byte[]
bytes=stringEntrada.getBytes(); |
|
|
| |
|
|
| |
i fer l'operació de trasllació,
un per un: |
|
| |
|
|
| |
int
quants=bytes.length;
for
(int i=0;i<quants;i++) {
bytes[i]=trasllada(bytes[i],encriptar);
} |
|
|
| |
|
|
| |
tot demanant el mètode private
byte trasllada (byte bIn,int mesOmenys) que has escrit abans. Ara
ja només cal construir la cadena ja encriptada: |
|
| |
|
|
| |
| stringSortida=new
String(bytes); |
|
|
| |
|
|
| |
i retornar-la. La classe, amb el
nou mètode incorporat, és així: |
|
| |
|
|
|
|
/**
* Encriptació i desencriptació pel mètode
del Cèsar restringit
* als caràcters ASCII imprimibles (32 a 126).
*
* @author Carles Romero
* @version 2004/01/10
*/
public class CesarASCII {
/**
* La translació que sofriran
els caràcters en encriptar (+)
* i/o desencriptar (-).
*/
int translacio=0;
/**
* Mètode constructor per a
aquesta encriptació del Cèsar.
* @param laTranslacio la translació
que sofriran els
* caràcters en encriptar (+)
i/o desencriptar (-)
*/
public CesarASCII (int laTranslacio) { //
constructor
translacio=laTranslacio;
}
private byte trasllada (byte bIn,int mesOmenys)
{
int iBIn=(int)bIn-32;
// Fer començar la codificació a 0
int mou=(mesOmenys*translacio)%95;
// del 32 al 126 hi
// ha
95 caràcters
if
(mou<0) { // Assegurar que mou >= 0
mou=mou+95;
}
iBIn=(iBIn+mou)%95;
iBIn=iBIn+32; //
Tornar a la codificació ASCII standard
return (byte)iBIn;
}
|
|
private
String encriptaOdesencripta
(String stringEntrada,int encriptar)
{
String
stringSortida=null;
if
(stringEntrada!=null) {
byte[]
bytes=stringEntrada.getBytes();
int
quants=bytes.length;
for
(int i=0;i<quants;i++) {
bytes[i]=trasllada(bytes[i],encriptar);
}
stringSortida=new
String(bytes);
}
return
stringSortida;
}
|
} |
|
|
| |
|
|
| |
Observa la precacució de
comprovar si stringEntrada és efectivament
una cadena ja construïda! |
|
| |
|
|
| |
Ara ja només queda escriure
els dos mètodes public per encriptar i
desencriptar: |
|
| |
|
|
|
|
/**
* Encriptació i desencriptació pel mètode
del Cèsar restringit
* als caràcters ASCII imprimibles (32 a 126).
*
* @author Carles Romero
* @version 2004/01/10
*/
public class CesarASCII {
/**
* La translació que sofriran
els caràcters en encriptar (+)
* i/o desencriptar (-).
*/
int translacio=0;
/**
* Mètode constructor per a
aquesta encriptació del Cèsar.
* @param laTranslacio la translació
que sofriran els
* caràcters en encriptar (+)
i/o desencriptar (-)
*/
public CesarASCII (int laTranslacio) { //
constructor
translacio=laTranslacio;
}
|
|
/**
* Encriptació segons aquesta
encriptació del Cèsar.
* @param string la cadena a encriptar
* @return la cadena encriptada
*/
public
String encripta (String string) {
return
encriptaOdesencripta(string,1);
}
/**
* Desencriptació segons aquesta
encriptació del Cèsar.
* @param string la cadena a desencriptar
* @return la cadena desencriptada
*/
public
String desEncripta (String string) {
return
encriptaOdesencripta(string,-1);
}
|
private
byte trasllada (byte bIn,int mesOmenys) {
int
iBIn=(int)bIn-32; // Fer començar
la codificació a 0
int
mou=(mesOmenys*translacio)%95; // del
32 al 126 hi
//
ha 95 caràcters
if
(mou<0) { // Assegurar que mou >=
0
mou=mou+95;
}
iBIn=(iBIn+mou)%95;
iBIn=iBIn+32;
// Tornar a la codificació ASCII
standard
return
(byte)iBIn;
}
private String encriptaOdesencripta
(String stringEntrada,int encriptar) {
String
stringSortida=null;
if
(stringEntrada!=null) {
byte[]
bytes=stringEntrada.getBytes();
int
quants=bytes.length;
for
(int i=0;i<quants;i++) {
bytes[i]=trasllada(bytes[i],encriptar);
}
stringSortida=new
String(bytes);
}
return
stringSortida;
}
} |
|
|
| |
|
|
|
Apa, a compilar i provar-la! |
|
| |
|
|
| |
Un exercici... |
|
| |
|
|
 |
Ara hauries de ser capaç
d'escriure una classe que posés en relació caràcters
i codis i que et fes les taules del principi d'aquesta pràctica.
L'esquelet de la classe pot ser aquest: |
|
| |
|
|
| |
/**
* Codificació de caràcters.
*
* @author (el teu nom)
* @version (un número de versió o la data)
*/
public final class CodisCaracters {
/**
* Caràcter corresponent a un
cert codi.
* @return el caràcter corresponent
al codi que es dóna
*/
public static char Codificacio (int codi)
{
//
posa el teu codi aquí...
}
/**
* Codi corresponent a un cert caràcter.
* @return el codi corresponent al
caràcter que es dóna
*/
public static int Codificacio (char caracter)
{
//
posa el teu codi aquí...
}
/**
* Codi corresponent al primer caràcter
d'una cadena.
* @return el codi corresponent al
primer caràcter de la
* cadena que es dóna
*/
public static int Codificacio (String lletra)
{
//
posa el teu codi aquí...
}
/**
* Impressió d'una llista de
parelles codi/caràcter a partir
* del caràcter 32 (espai).
* @param finsElCaracter el límit
superior de la llista (ha de
* ser un nombre enter múltiple
de 4
*/
public static void llistaCodificacio (int
finsElCaracter) {
//
posa el teu codi aquí...
}
}
|
|
|
| |
|
|
| |
Els
tres primers mètodes no són gens difícils i, amb una
sola línia de codi a cadascún d'ells n'hi hauria d'haver prou:
tot consisteix en un bon ús del càsting... |
|
| |
|
|
| |
En canvi, el mètode public
static void llistaCodificacio (int finsElCaracter) é |